


I’m sure you want to build scalable apps, right? Who doesn’t? If so, you must have come across the words “Cloud Native.” This approach is like an angel which can resolve most of your scaling challenges. So, what exactly is cloud native?
Cloud native is an approach used to build apps which can harness all the capabilities of the cloud.
Yup, you got that right. It’s an approach. Not a framework. Not a bunch of steps to follow. And due to this, there are a million different approaches to go cloud native and achieve cloud computing “Moksha.”
One key principle of cloud native is microservices. Microservices are tiny (sometimes not so tiny) modules which can work independently of each other. They could have dependencies on other microservices or even a data persistence layer like a database. But the key is to use loose-coupling. Microservices coordinate by means of “communication.”
This means each microservice sits in a different repository and is being deployed independently. For the DevOps folks out there, you have an independent continuous delivery pipeline dedicated to each microservice.
But that brings me to the most important question.
How can we make microservices talk?
Keeping aside the difficulties in deciding on a “forward compatible” API for microservices, just making them talk isn’t as simple as it looks. There are multiple parameters you need to consider. These are throughput, latency, and scalability.
Now there are many ways to classify the different modes of communication. Synchronous (blocking) and asynchronous (non-blocking) are used quite often, but I feel these are mostly the characteristics of a programing language. I’m also going to disregard half vs. full duplex modes since these days it’s very easy to use either (or even both) in most cloud architectures.
So let’s dive in.
The Brokerless Design
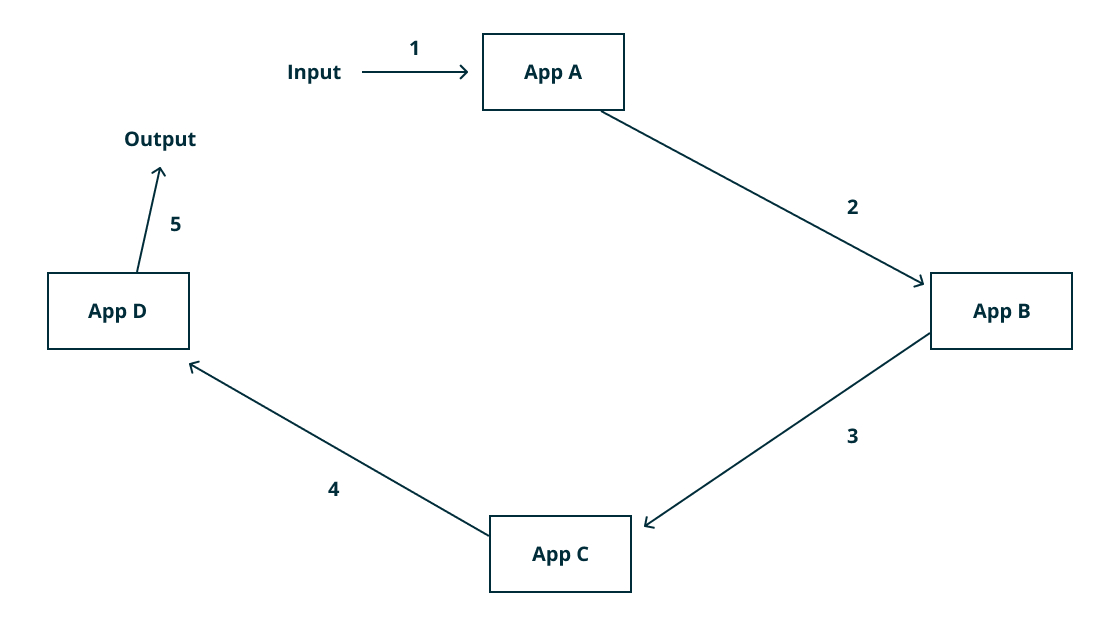
What it is: In here we make our microservices talk to each other directly. You could use HTTP for traditional request-response or use websockets (or HTTP2) for streaming.
There is absolutely no intermediary nodes (except routers and load balancers) between two or more microservices. You can connect to any service directly, provided you know their service address and the API used by them.
Sounds pretty basic right? It pretty much is. There are wonderful protocols like GRPC to make life much easier.
The Pros:
-
Low Latency: This method has the lowest latency possible. There is no middle man here. It’s fast. The limitations are imposed mostly due to poor API implementations. But again, tools like GRPC make sure you get maximum performance at the API layer.
-
Easy to Implement: A brokerless design is easy to visualise and implement. This makes life much easier and the world a happier place to live in.
-
Easy Debugging: This method is fairly easy to debug, especially from the next one I’m going to talk about. Debugging or tracing where the errors are is a super important topic in distributed systems. This becomes even more important when you are releasing new updates multiple times a day.
-
High Throughput: In this mechanism more CPU cycles are actually spent on doing work rather than routing. It may not be that apparent now, but a broker design would make this a bit more clear. It’s not a surprise that most of the database APIs actually use a brokerless design.
The Cons:
-
Service Discovery: In such a design, service discovery has utmost importance. The service discovery mechanism needs to be responsive and scalable enough to reflect the latest state of the cluster.
-
Connection Nightmare: Imagine if all the microservices need to connect to each other. That would be a lot of connections. Most of these connections are fairly idle. As a result, a lot of resources are wasted due to this.
-
Tightly Coupled: By nature, brokerless designs are tightly coupled. Imagine you have a microservice to process online payments. Now you want another microservice to give you a real-time update of number of payments happening per minute. This will require you to make modifications in multiple microservices which is undesirable.
In many cases a brokerless design just doesn’t work. You often have requirements to simply publish the message once and have multiple subscribers consume it. This is where a broker design comes into the picture.
The Messaging Bus (Broker) Design
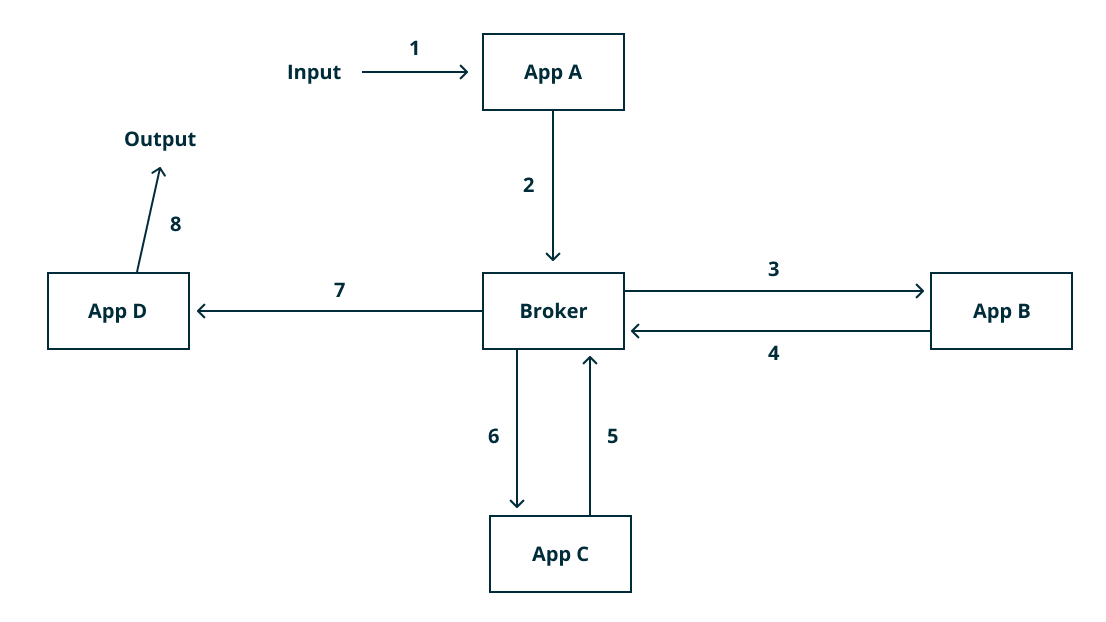
What it is: In this architecture, all communication is routed via a group of brokers. Brokers are server programs running some advanced routing algorithms.
Each microservice connects to a broker. The microservice can send and receive messages via the same connection. The service sending messages is called a publisher and receiver is called a subscriber. Messages are published to a particular “topic.” A subscriber receives those messages for topics to which it has subscribed.
The Pros:
-
Load Balancing: Most messaging brokers support load balancing out of the box. This makes the overall architecture much simpler and highly scalable. Some brokers (like RabbitMQ) have built-in retries and more for making the communication channel more reliable.
-
Service Discovery: Service discovery is not required when using a messaging backend. All microservices act as clients. The only service which needs to be discoverable is the message broker.
-
Fan In and Fan Out: A messaging backend makes it easier to distribute workload and aggregate the results. The best part is that adding worker microservices can be done transparently without having to update the other microservices.
Stream Based Design: Such an approach also gives birth to a concept of streams. Each topic is essentially a stream of messages. Any subscriber can tap into these streams as and when required. The possibilities of modeling a system design using streams is endless.
The Cons:
-
Scaling the brokers: While the advantages are amazing, scaling the brokers themselves becomes a challenge for highly distributed systems. It’s just another piece to maintain alongside your microservices.
-
Higher Latency: The number of hops in a message bus increases the overall latency. This is especially true for a RPC-like use case. In mission critical apps, this might not be a feasible solution.
-
Higher Resource Utilization: The brokers need CPU, memory, and storage resources to run. These resources could otherwise be utilized for running other microservices. The overheads associated with a broker design could be too much for a small cluster.
Just knowing the advantage and disadvantage of various architectures isn’t enough. It is important to know when to use what.
You must always default to a brokerless design. Make the switch if you need the flexibility of streams or need to leverage the pub-sub semantics of a message bus. If you’re starting off fresh, it would make sense to start with a brokerless design and then switch once the need rises.
It’s not necessary to choose just one. You can use both. For our tool, we are using a broker design to implement the RPC calls. The communication with our database layer is brokerless to provide lower latencies.
Wrapping Up
Using the right approach for the job is important. Choosing the mode of communication is a fundamental decision which needs to be taken with great care.
There are multiple options for both. Sticking to a well established framework almost always makes more sense than making something from scratch. There are so many options out there. For message brokers you’ve got RabbitMQ, Nats, Kafka, etc., and each one is built for particular messaging semantics.
Another awesome way is to use a Backend as a Service like Space Cloud. Space Cloud will automate the entire backend so you can focus on the business logic rather than the the cloud architecture.
Did this article help you? How do you make sure your apps are cloud native? Share your experiences below.







