

While microservices offer tremendous benefits and help you stay agile, it’s important to get them right.
In this post, we are going to see how the nature of microservices makes choosing the right API layer even more important and how GraphQL perfectly fits in it.
At the end, we have also listed some key points that you need to keep in mind while adopting GraphQL in your microservices.
What are Microservices?
Microservices based architecture is a design pattern and not a framework.
While there is no precise definition of what microservices are, it loosely corresponds to architecting your single application as a suite of smaller services that are:
- Organized around business capabilities.
- Have a single responsibility.
- Owned by a small team.
- Loosely coupled.
- Independently deployable.
- Highly maintainable and testable.
Before diving deep into microservices and why they need GraphQL, let’s compare it with monoliths to get a clearer global picture.
Microservices vs monoliths
Unlike monoliths, in microservices architecture, we have different services, each taking ownership of a particular part of data. Let’s take an example to understand this.
Consider the feeds page of Instagram. A simple page like this has various features in it:
- Showing a personalized list of feeds/posts.
- Showing details of the post author (name, image).
- Showing the likes and comments of a post.
Unlike monoliths, in a microservice architecture, there are different services for each of the above feature.
If you are thinking what’s so cool about splitting our app in such a way, it’s useful to consider the following benefits of doing so:
- Independently deployable: Changes in one part of our application doesn’t mean deploying the whole application again, leading to shorter QA and release cycles.
- Increased productivity and confidence: Each team owns a small codebase which is easier to understand and test.
- Easy to migrate and optimize: You can build different services with different technologies (languages, frameworks, databases) as per the task and team resources.
Already excited and want to get started with microservices?😛 Won’t stop you from doing so, however, there are certain things that you need to be careful of before adopting microservices. One such thing is choosing the right API layer for your microservices.
Why your microservices shouldn’t REST
Although REST has some inherent shortcomings, it is still the most popular choice of API for many. However, the nature of microservices tends to make the problems with REST even more severe.
Let’s look at some key points on how REST degrades our microservice architecture.
Multiple requests
With REST, the simple feeds page that we saw above has to make requests to multiple services (feeds service, user details service, comments service)
The problems become even worse when these requests need to be joint. For example, in our feeds page, we can request the user details and comments microservices only after we have the results from the feeds list service.
This requirement of joining requests due to the relational nature of data leads to increased latency and poor UX. Remember that a few seconds of delay is all it takes for the user to close the tab and move to some other alternative. No! We don’t want that to happen with us 😭. Who would!?
N+1 problem
If you have been consuming the GraphQL diet consistently, you would have surely been served the N+1 dish by the GraphQL advocates till now! 😁 If not, then don’t worry, heres a teaser.
If you remember, our app had a service to fetch the details of a user?
Typically we would design this service to take a single user id and return the details of the corresponding user. However, each post in our feeds page can potentially belong to a different user.
This means we would have to make one request to fetch all the posts and then N requests to fetch the details of each post author where N is the number of posts.
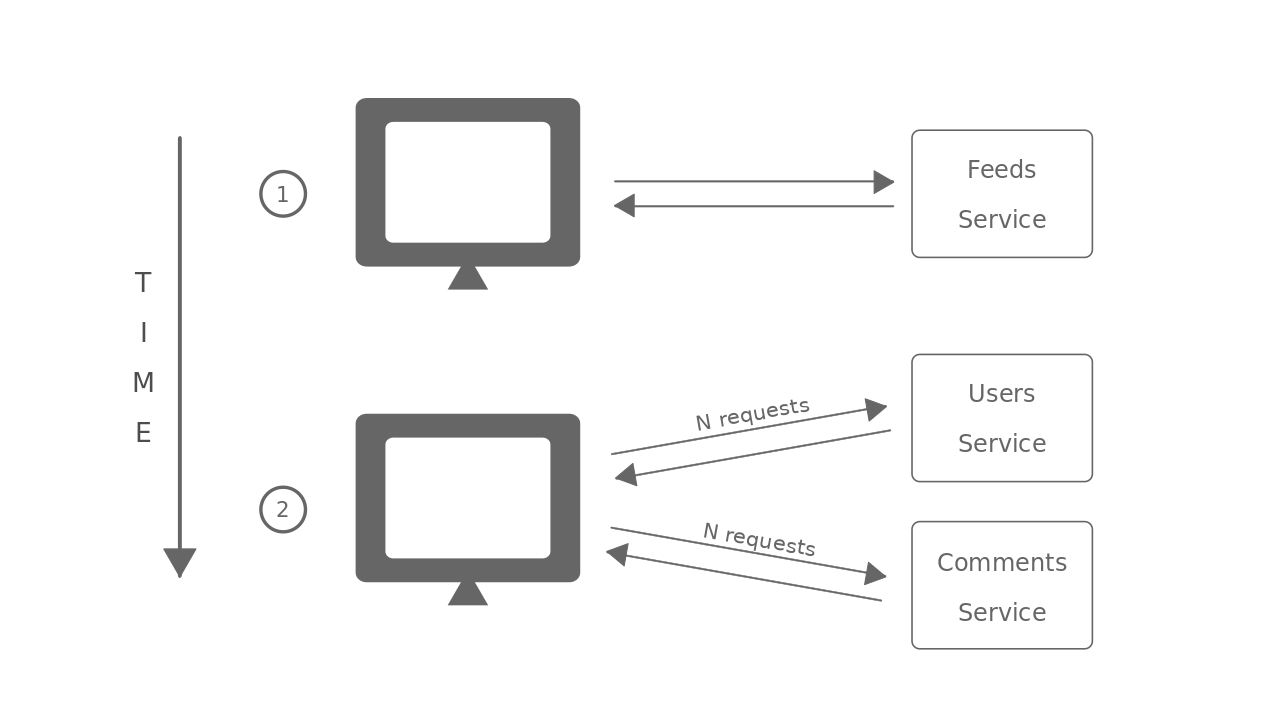
And this is just a simple example. You can imagine how easily this situation can cascade to a networking nightmare in a real world scenario.
If you are anything like me, you would have already started thinking of solutions in your head 😇.
Let’s think of some right now 😋!
An aggregator service in front of feeds and user details service can reduce the latency by enforcing the joining of requests on the backend rather than frontend!
This surely helps but its yet another service that you need to deploy and maintain 😅. And if you think monitoring a monolith was hard, monitoring microservices is 10x harder.
You could also tweak your user details microservices to take an array of users ids and return details of all those users at once.
Wait… you already thought of that? If yes, then I’d love to meet you for a cup of coffee 😛.
Nevertheless, the problems don’t end here.
Bandwidth
In most cases, our user details service would return a whole lot of other information as well apart from the name and profile picture.
Information like email, bio, address, date of birth and phone number could be required by other pages of our app.
You might think that these extra fields adds barely a few KBs to the payload. Multiply this number by the number of posts present in the feed and by how many times the feed is viewed in a day.
This problem is typically referred to as over fetching in the API world.
So should we ban microservices?
No. Not yet.
Remember why we use them in the first place. Its for agility, right?
That’s got nothing to do with the above problems.
Microservices is a brilliant concept in itself when used correctly.
The problem lies in the multi-facet demands of the business.
On the agility side, it requires us to architect our app into smaller services, while on the UX side it demands us to join data from various sources to provide a unified and enriching experience to our users.
Its almost like we need to build a monolith and a microservices based architecture at the same time.
To bridge this gap, we need a unified API layer in front of our microservices that is smart enough to fetch and combine data dynamically from various sources.
I know you have already guessed it. Its GraphQL.
What is GraphQL?
GraphQL is a query language for your APIs. As compared to REST, the GraphQL server has a single endpoint.
Instead of making multiple requests to different endpoints, we send a single GraphQL query string describing our data needs to the GraphQL server.
Think of it as SQL for your API server.
The GraphQL server is smart enough to interpret this query and request the concerned data-sources (microservices in our cases) to return only the data required by the client.
Let’s take our Instagram example once again. Here’s how the client can describe its data requirements in a single GraphQL query for it:
query {
feeds {
id
content
author {
id
name
}
comments {
comment
created_at
user_id
}
}
}
Notice how the above nested GraphQL query also clearly indicates the request chaining pattern required to be performed by the GraphQL server.
This is how the GraphQL server makes requests to our microservices as per the GraphQL query:
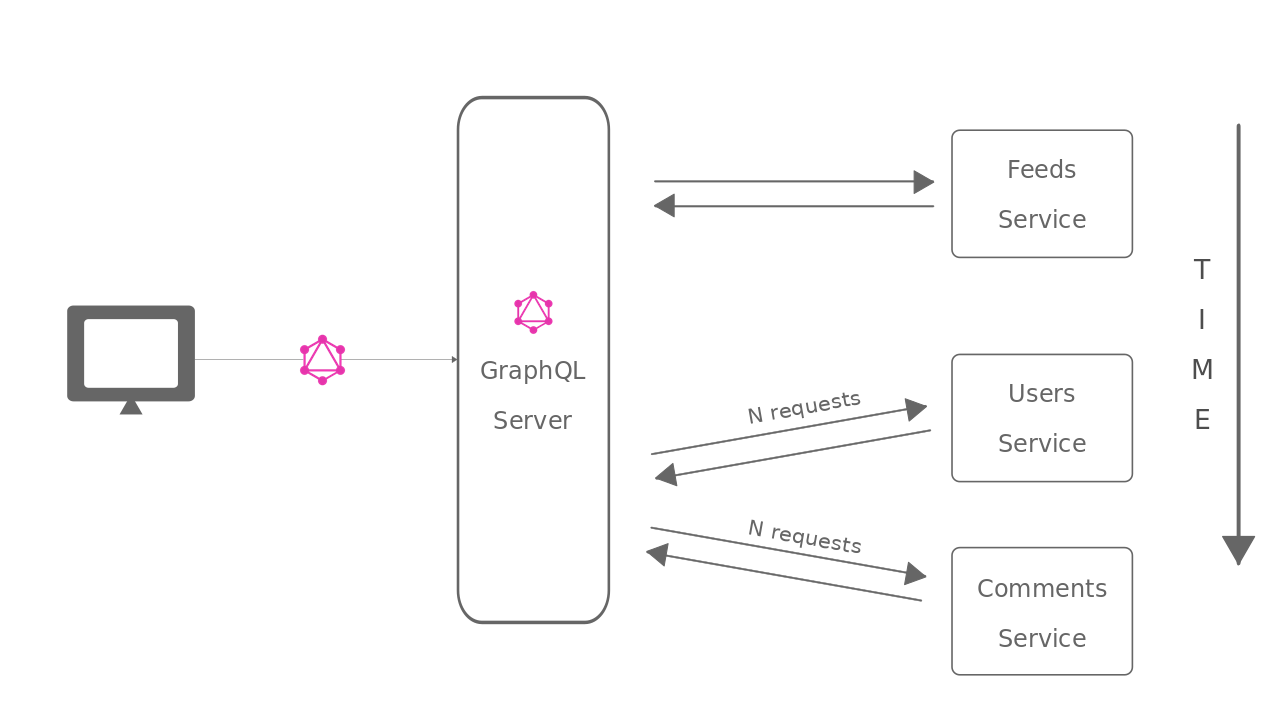
The graphql server resolves the request from left to right. That’s why it first requests the feeds microservices since it comes first from the left.
After getting the response from the feeds service, it then makes the request to the user details and comments service parallelly as they are at the same level inside the feeds request in the GraphQL query string.
Note that the N+1 requests happening here are between the GraphQL server and the microservices. These N+1 requests are of very low latency because they are part of the same network.
Apart from shifting the N+1 request from frontend to backend and making a single request, GraphQL sends the values of only the requested fields back to the client. Thus we have ticked all the problems that we had using REST with microservices.
That’s the reason why I firmly believe that any microservice architecture should have GraphQL as its API layer.
Excited for GraphQL as you were for microservices? 😛 Let’s take a step back and tackle some of the stepping stones that you may face while adopting GraphQL.
Adopting GraphQL
While GraphQL is amazing, its relatively new and the world is still catching up with it. Here are some gotchas that you need to be aware of before using GraphQL in your microservices architecture:
It has a fixed schema: While this is one of the strongest selling points of GraphQL, one may hate writing a schema if he/she prefers the schemaless way of doing things. This can be especially true if you love Javascript more than Typescript or MongoDB more than SQL. Did I just start a war here?
Implementing resolvers: In GraphQL, you need to write resolvers on the backend that resolve data for a particular field/type as opposed to writing request handlers for endpoints. This is a new way of writing API servers, and you might have a hard time initially understanding how resolvers work.
Optimizations: As we saw earlier in our Instagram example, the GraphQL server itself has to make N+1 requests to fulfil relational/nested requests. You can use the Dataloader pattern to reduce the number of requests that the GraphQL server makes. No need for premature optimizations early on, but this is something you should surely keep in your mind as your applications start scaling.
Security: In GraphQL you have to secure fields as opposed to endpoints in REST. Securing endpoints is way easier than securing fields. Implementing field level authorization can be tricky to get right at first.
Migrating existing REST APIs: What if you already have tons of microservices in REST already deployed in production? Migrating existing REST APIs can be a very daunting task. This guide on migrating existing REST APIs to GraphQL can help you incrementally do that.
Husshhh😅! That was a lot. If you are overwhelmed by today’s GraphQL dose and want an easier way to adopt GraphQL for your microservices, don’t worry, I have a bonus for you.
Bonus: Space Cloud as a GraphQL layer
Implementing GraphQL from scratch can be overwhelming at first, especially if you aren’t used to it. But you also don’t want to miss on the amazing benefits that GraphQL has to offer. That’s why we have made Space Cloud - An open source GraphQL layer.
It connects to your existing databases and REST services and provides a unified GraphQL API on top of them which you can use securely from the frontend.
The best part?
You get all the GraphQL goodness without making any changes to your existing REST APIs.
Sounds exciting?
Check out the step by step guide to get started with Space Cloud. And yes, don’t forget to star us on Github if you love Space Cloud and GraphQL♥️.
Also, feel free to reach out to us on our discord server - link missing or directly put a comment below.







