

We are living in the containers era right now. Everyone seems to be using them. Those who aren’t already are on the journey to adopt it.
The thing is, containers alone don’t solve all your problems. You need a way to run them.
And what’s the best way to run containers?
It’s Kubernetes!!!
Kubernetes has clearly won the orchestration wars. All major cloud providers like Google, AWS, Azure and even DigitalOcean offer a managed Kubernetes solution.
We recently moved to Kubernetes from VMs at SpaceUpTech. In this article, I’ll be talking about how we achieved precisely that.
I must add that this isn’t a getting started with Kubernetes guide. This is more of a moving to Kubernetes guide. However, if you are new, you can use it to note the steps you’ll need to follow.
Always Start with Preparations
Let’s start with this.
Moving to Kubernetes is not a one step process.
You can’t move to Kubernetes overnight. That’s just the way it is.
This means that this isn’t the usual X mins to achieve Y guide. You will have to invest some time in carefully planning on how to go about it.
Moving to Kubernetes is like moving to another apartment.
You need to start by packaging all your furniture and belongings. Then you move them to the new apartment without breaking anything. And trust me, things break!
But you can’t just unpack everything yet.
You might want to make some adjustments to the new apartment like re-painting everything or what not.
And let’s not forget the most difficult part. You need to decide what goes where!!
If you are lucky and have more or less the same layout, you will be able to move things as is. If you aren’t that lucky, you might have to re-architect things here and there.
Those who have the luxury of time and money choose to use this opportunity to buy everything and start afresh.
The point is, you’ll have to plan this out to get things done.
You might be thinking that given my deep knowledge in setting up apartments, I might be some real-estate guy. You are partially correct. I am an Architect. A Cloud Architect! 😜
Keeping my lame jokes aside you probably know what I’m talking about. I bet you have already associated each activity I’ve mentioned with a task you’ll need to do.
So let’s get to it! Let’s move our application to Kubernetes.
Package Everything As Containers

You need to have a count of what services you are running. You also need to know what are their dependencies.
Whether you choose to build everything from scratch or not, you cannot avoid this step.
Kubernetes runs containers not code. In short, you’ll need to package your code/artifacts to containers as the first step.
Know your dependencies
I think it’s important to cover this topic. This is where we had made a major mistake.
While building a Docker image for each one of your services, you need to install the dependencies required by that service.
For example, your Spring app needs the JVM to run. Similarly Nodejs would require… well… Nodejs! 😅
You might also need to install OS level packages in some cases.
But dependencies are not just limited to things you need to include in your docker image. There is a little more to it.
We learned it the hard way.
One of the services we ran was a gateway which exposed our Rest APIs and database via. GraphQL. You might already be aware of this as we have released it as an open source project called Space Cloud.
Our gateway relied on a config file. Initially we packaged this config file as a part of the docker image.
This was a terrible decision.
We had to redeploy the image every time we made a change in the config file. It used to get super annoying to wait for the docker image to get built and uploaded.
Another one of our services needs to speak to all of its replica to keep certain data in sync. In essence, we had a dependency on the IP of each instance of that service. We needed the IP addresses for each replica to be constant.
Things like storage and network dependencies need to be identified upfront.
It might not influence the way you build your containers. But it does influence how you run them. Documenting these little things will help you out in the next step.
To sum things up.
List down the environment, storage and network dependencies for each one of your containers.
So go ahead and do this for any one service. I’ll wait!
.
.
.
Don’t cheat.
.
.
.
Seriously!?
Go do it for any one service.
.
.
.
Hmmmm…
.
.
.
So you finally decided to not do it.
For those who did, you deserve a pat on the back. And those who didn’t, you’ve hurt my feelings! 😢
Uploading your Docker images to a registry
Just building docker images isn’t enough. You need to push them to a docker registry.
This is important.
We will have to provide the url of the docker image to Kubernetes so it knows what image to pull from where.
I usually recommend using the Docker registry provided by the cloud vendors. They usually have direct integration with Kubernetes so you can pull private images without having to provide credentials.
You can use Docker hub for all public images.
Mapping Your Requirements To Kubernetes
Okay, its time to get serious now. This is by far the most intensive step.
Now is a good time to brush up your Kubernetes skills before we move forward. If you are new to the Kubernetes world, don’t worry. I’ll try to make this guide as complete as possible.
I will be linking out to specific pages in the Kubernetes docs for more information.
Luckily, we don’t need to worry about setting up Kubernetes. As I mentioned above, most cloud vendors provide a managed Kubernetes solution. Gone are the days of doing Kubernetes the hard way. 😜
I would encourage you to check out that guide if you are interested in learning the nuts and bolts of Kubernetes.
We chose GCP primarily because Google was the one who came up with Kubernetes. No other reasons.
So lets get to mapping your services to Kubernetes.
Stateful or Stateless?
This is the burning question.
All the hard work you’ve put in listing down your dependencies is gonna pay off now.
Oh wait! I remember… You didn’t. You can still go back and do it now! 🙃
Answering the stateful vs stateless question is important. Kubernetes has different operators to manage both of them. So how can you decide whether your application is stateful or stateless?
Its easy.
Just have a look at your dependencies!
Okay Okay. Let me elaborate a bit.
If your service depends on a resource beyond its own lifecycle, your service is stateful.
Let’s take a few examples.
-
A database depends on the files it created in the local filesystem. These files are required even after the database is restarted. The database will use these files to resume from where it left off.
-
An in-memory pub-sub needs to know the existence of its peer nodes. To enable auto-discovery, its important for the
seednodes to have static IP addresses or DNS names. These addresses need to be static even after the peers restart.
The examples above have state in the form of storage and network dependencies respectively. More importantly, their dependency exists beyond their own lifecycle.
You must always default to stateless services unless they have dependencies which exist beyond their own lifecycle
The reason is simple.
Stateless services are easier to scale and manage.
At SpaceUpTech, our initial inclination was towards deploying each service as a stateful one. We did this in order to be future ready.
If it isn’t already clear, this wasn’t the right attitude.
There are several ways you can convert seemingly stateful services to stateless.
-
Configuration metadata is not state. Many people mistake configuration metadata as state. That’s not true. Store configuration metadata as ConfigMaps or Secrets. Kubernetes can mount these as files or environment variables at runtime.
-
Move sessional data to an external store. It’s not a good practice to store sessional information like session ids within your service. It’s wise to move this to redis or memcache. This will make scaling the service a lot easier as well.
-
Don’t consider cache as state. We cache certain objects aggressively for performance. Initially, we would consider the services which cached data as stateful. Practically speaking, this is not required.
Working with stateless services
In Kubernetes, each instance of your service runs as a Pod. To be accurate, a pod consists of one or more containers.
You might be thinking why do we need that?
In many cases, we require running worker containers adjacent to our container for secondary tasks. I’m talking about tasks like exporting logs, monitoring health, etc.
You don’t need to worry about all of this now.
But the thing is, there is no mechanism in the pod itself for scaling and self healing. This does makes sense. Both of these elements are outside the scope of a single pod’s lifecycle.
But we do want all the awesomeness of defining the replicas we want for our services right? And why are we even moving to Kubernetes if services can’t be restarted on infrastructure failures?
Worry not. Lord Kubernetes has us covered!
Kubernetes provides a Deployments controller. To be more specific, a Deployment provides declarative updates for Pods.
This means you describe the desired state for a specific deployment, like the env variables to apply, the number of replicas required and the docker image to use. Now it’s the Deployments Controller’s responsibility to achieve the desired state.
So if a VM fails for any reason, the Deployments controller will automatically start new pods to maintain the required number of replicas in the cluster.
Pretty cool right?
A deployments object looks something like this.
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-service
labels:
app: my-service
spec:
replicas: 3
selector:
matchLabels:
app: my-service
template:
metadata:
labels:
app: my-service
spec:
containers:
- name: my-service
image: my-org/my-service-image:0.1.0
env:
# Define the environment variable
- name: SOME_VAR
valueFrom:
configMapKeyRef:
# The ConfigMap containing the value you want to assign to SOME_VAR
name: my-config
# Specify the key associated with the value
key: some-key
ports:
- containerPort: 8080
As you can see, in this example I’ve created a deployment object named my-service.
This deployment will deploy 3 replicas of single container pods. The image to be used is my-org/my-service-image:0.1.0. I’m also mounting an environment variable from a configMap named my-config.
Kubernetes config is generally stored as YAML files and can be applied using the kubectl apply -f <filename>.yaml command.
We need to keep in mind that this only deploys a service. It doesn’t provide our pods a dns name which can be used to access our pods.
For that, we need to create a Service.
Here’s how the service for our deployment would look like:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: my-service
ports:
- protocol: TCP
port: 8080
This would make our service accessible as my-service and automatically set up load balancing between all the pods. A request to this service would look something like this: http://my-service:8080/some/path.
If you have been following me till now, Deployments and Services together take care of configuration management and service discovery requirements for our services as well.
We often define Services and deployments in the same file. Like this:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: my-service
ports:
- protocol: TCP
port: 8080
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-service
labels:
app: my-service
spec:
replicas: 3
selector:
matchLabels:
app: my-service
template:
metadata:
labels:
app: my-service
spec:
containers:
- name: my-service
image: my-org/my-service-image:0.1.0
env:
# Define the environment variable
- name: SOME_VAR
valueFrom:
configMapKeyRef:
# The ConfigMap containing the value you want to assign to SOME_VAR
name: my-config
# Specify the key associated with the value
key: some-key
ports:
- containerPort: 8080
The order doesn’t really matter here.
Can’t all of this be a bit easier?
That’s the unanimous question our entire team asked. I know you won’t believe this, but they all asked this in chorus. I still remember their faces. It was hilarious! Memories! ❤️
But let’s be practical here. This entire exercise doesn’t make a lot of sense if the team wasn’t with us.
We had to take a call.
Make Kubernetes easier or scrap the entire migration.
We are a dev team, and not all of us had experience dealing with DevOps and Kubernetes. A tool which nobody wants to use is useless.
We build an automation tool named runner, which auto-generated these Kubernetes config files. We slowly added features based on our requirements.
I’m talking about things like managing secrets and an easy to use admin UI.
Meanwhile. some of us were also having a look at Services Meshes. Istio stood out. So we also added native Istio support to runner.
In my previous articles, I’ve spoken about why service meshes are important for your microservices and compared the popular services meshes out there.
Today runner is capable of deploying stateless services to Kubernetes within Istio. It takes care of setting up mtls and encryption for inter-service communication. It also has a traffic splitting mechanism to carry out canary deployments and A/B tests.
We were so happy with the results that we have open sourced runner and released it as a part Space Cloud.
You can check out this step-by-step guide to deploy your applications on Kubernetes with Space Cloud without having to go through the learning curve.
Working with stateful services
Okay. Time to move on now.
At SpaceUpTech, we tend to avoid using stateful services altogether. The only stateful set we have is the gateway component of SpaceCloud.
We did not even add stateful service support to runner to discourage the use of stateful services.
However, I do understand that you may have some stateful services that you need to run. So let’s quickly go through how you can do that.
Kubernetes provides another controller named StatefulSets to work with Stateful services.
Fortunately, the configuration of a StatefulSet is similar to a Deployment. StatefulSets, too, require a special type of Service, called a Headless Service, to accompany it.
Here’s a sample:
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
selector:
matchLabels:
app: nginx # Label selector that determines which Pods belong to the StatefulSet
# Must match spec: template: metadata: labels
serviceName: "nginx"
replicas: 3
template:
metadata:
labels:
app: nginx # Pod template's label selector
spec:
terminationGracePeriodSeconds: 10
containers:
- name: nginx
image: gcr.io/google_containers/nginx-slim:0.8
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 1Gi
You may have noticed that the service config has an additional clusterIP: None field. To put things simply, this creates a unique domain name for each replica in that service.
You can access individual replicas in the above example as nginx-0, nginx-1 and so on.
Another cool aspect is the volumeClaimTemplates.
This essentially attaches a block storage device to the container. In our example, a block storage device of size 1Gi will be created and attached to each replica.
The same block storage device is reattached to the container in case it is restarted due to any reason.
I know all this sounds super awesome. But you cannot use this as an excuse to exploit StatefulSets. All this functionality comes at a cost.
Setting up Ingress
You will have to publish a service using a service type in order to make it accessible from the external world. I won’t be diving into this much.
Normally services are accessible from within the cluster only. By setting the service type to NodePort or LoadBalancer you are able to make it accessible from outside.
Service type NodePort exposes the service on a specified port of each Kubernetes node while type LoadBalancer provisions a loadbalancer to handle incoming traffic. The target of the load balancer will be your service.
You must almost always use type LoadBalancer in production.
You can refer to the documentation for more info.
Making the Switch
By now you should have the Kubernetes YAML files we will use to deploy your services stored in a directory. If the steps till here have been tricky or vague, feel free to ask questions in the comments or ping me on twitter.
The next step is deploying our services. All you need to do is run a simple command: kubectl apply -f <config-dir>.
This will apply all the config to your Kubernetes cluster. From that configuration, Kubernetes will know which services to deploy. It will also setup the necessary volumes and environment variables that you may have listed down.
I usually suggest trying out Kubernetes locally with Minikube or Microk8s. If you are interested in using Kubernetes with Space Cloud to simply things, you can refer to this guide.
Once everything works as expected in a local environment, you can deploy your services in production.
Transitioning traffic from VMs to Kubernetes
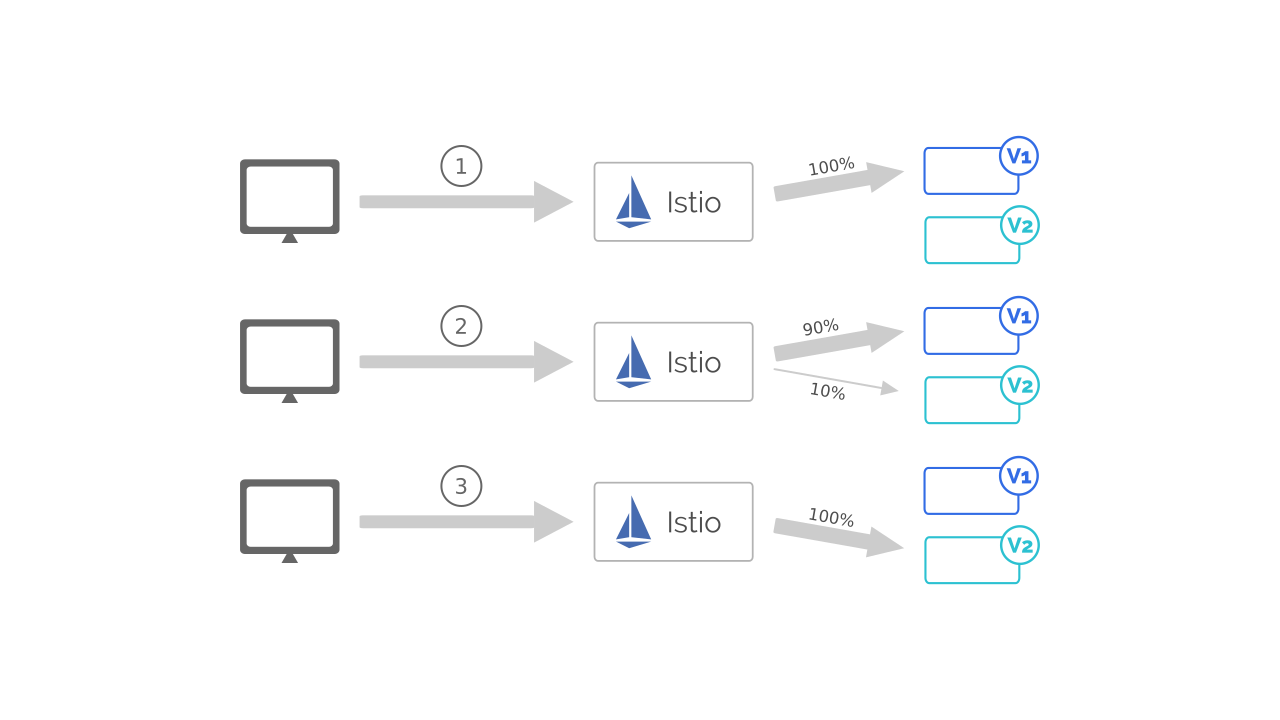
My journey had one small hiccup.
Our VM based infra was already serving live traffic. We wanted to make the switch without disrupting existing traffic.
On top of that, we still had to test our Kubernetes environment against production traffic. It would be a disaster if things would crash after we made the switch.
We needed a way to migrate live traffic incrementally to our Kubernetes cluster.
This is where the decision to use Istio paid off.
We used Istio’s traffic splitting functionality to direct all ingress traffic (coming to Kubernetes) to our VM infrastructure.
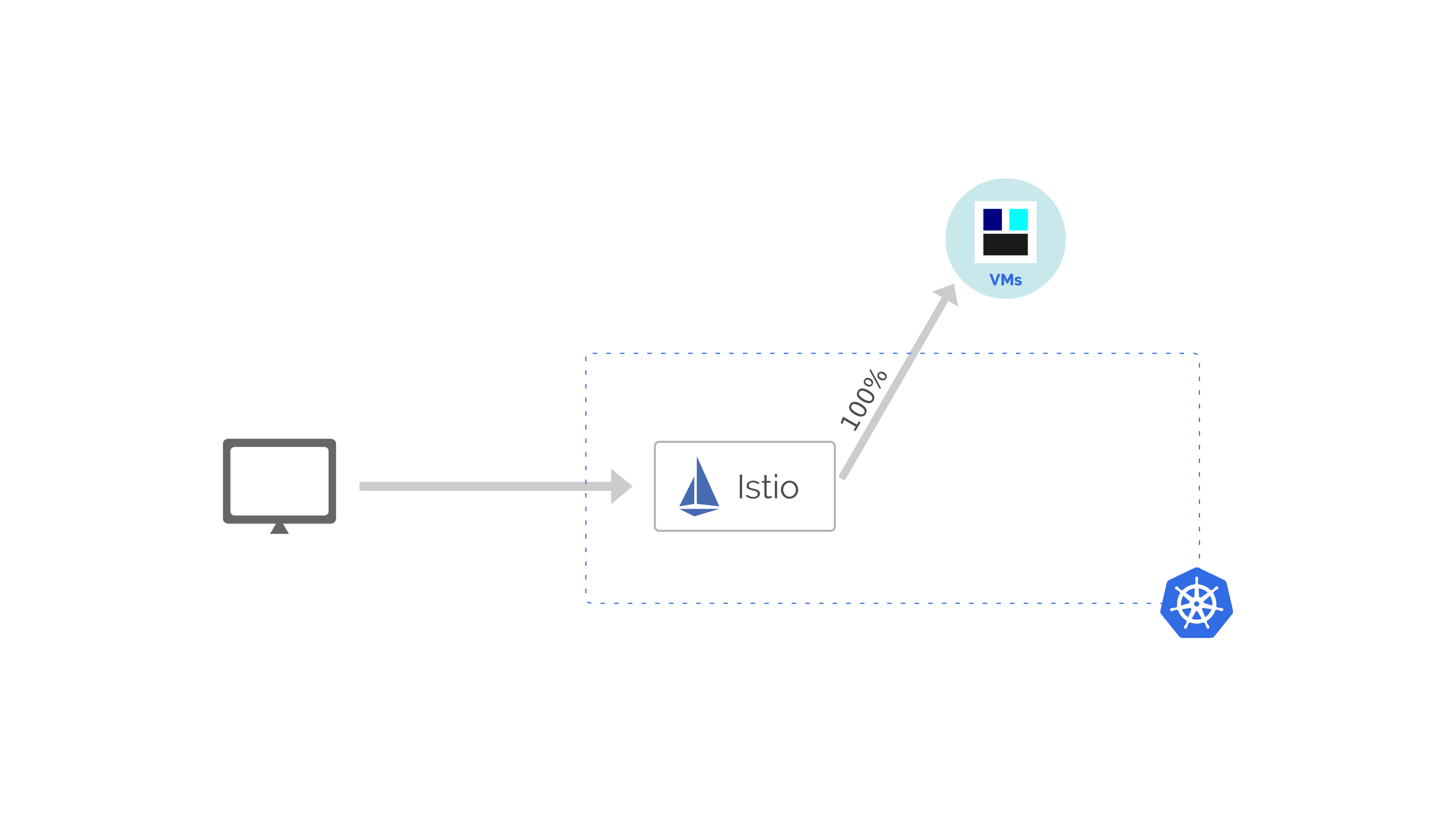
In short, we were using our Kubernetes infrastructure as a mere API gateway to begin with.
Once we have made this change, we switched our DNS systems to point to our Kubernetes cluster. As expected, Istio was routing all incoming traffic to VM infrastructure where it was getting processed.
Once we had this setup in place, we went for the next step. We split a small fraction of our traffic (10%) to the Kubernetes services.
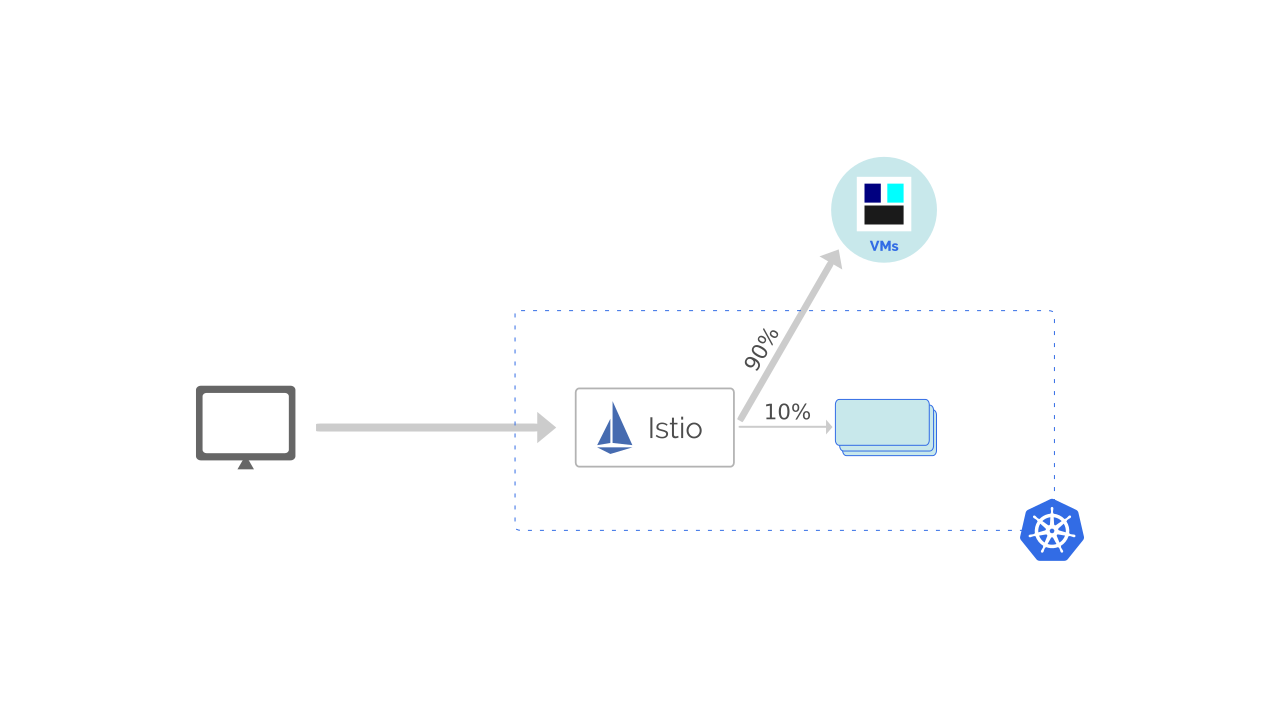
We let this setup be for a few days to verify if the services in Kubernetes were processing it’s share of requests reliably.
We moved all incoming traffic to Kubernetes once we were confident with the setup.
I highly recommend this approach whenever moving to Kubernetes. In fact, we still use this method to deploy new versions of our services. We test the new version with a subset of production traffic before making the switch.
To simplify this process, we added support for traffic splitting in Space Cloud which lets us do all of this simply via a UI. This way, our team need not worry about learning Istio.
Post Migration Steps
Our journey did not end after moving to Kubernetes. We faced some problems even after the migration was successful.
Many guides leave out the post-migration scenario. That’s why I’ve made an attempt to describe the changes we had to make in our development practices.
Strategy for local development
This was by far the most affected domain. Local development and testing had become increasingly hard by adding Kubernetes to the mix.
It is quite demanding to run a Kubernetes cluster on your laptop. Not all of our devs had a high-end laptop.
We do have a dev environment, but local testing has always been a part of our practices. We just count not ignore this aspect of development.
Initially, we tried to develop and test locally without kubernetes. This worked great. But we faced a lot of issues with the Kubernetes configuration when it came to the dev environment.
We decided that we want a consistent experience on the local, dev and production environments.
One way to achieve this was by using Docker for local development. The challenge was the inconsistency of the Docker and Kubernetes cli tools.
We realized that we were already using Space Cloud for handling all deployments. What if Space Cloud could provide us with the same features for Docker?
After some tinkering, we added Docker support to Space Cloud. Today, Space Cloud supports Kubernetes and Docker as target environments for deploying services. It also provides features like traffic splitting so we can rest assured that config that works locally will work in production as well.
Developer experience.
Working with Docker and Kubernetes added a bit of a learning curve to our developers. Even with Space Cloud, they still had to write Dockerfiles, config files, build and push docker images.
This slowed down development speed.
To tackle this, we added a space-cli deploy command to our cli. This tool was a tiny wrapper on the Docker and Space Cloud commands one might need to deploy a service.
We also added a space-cli deploy --prepare command to generate a Dockerfile and config file with smart defaults.
So do you have to use Space Cloud to do anything meaningful with Kubernetes?
No. Not at all.
I would wish so, but you honestly don’t.
I still find myself writing Kubernetes and Istio config files for certain niche tasks. No one can beat the flexibility the raw API provides.
There are several other tools you can use which achieves similar results. Here are a few we tried out before building runner.
- Garden - https://garden.io/
- Skaffold - https://skaffold.dev/
- Draft - https://draft.sh/
Concluding
Like all great journeys, this one had to come to an end as well.
All I wish for is you have gained a little by hearing me out. Do let me know on twitter or in the comments in case you wish to talk to me regarding moving to Kubernetes.
If you like this article, do share it with those it may help as well.
Don’t forget to star Space Cloud on GitHub.







